

CPython Garbage Collection: The Internal Mechanics and Algorithms
A detailed code walkthrough of how CPython implements memory management, including reference counting and garbage collection

We’ve been talking about CPython internals and in the last article I went quite deep in CPython’s runtime. One of the crucial services that the runtime provides is that of managing a program’s memory during execution.
Our programs have to create objects to do their tasks and these objects consume memory. Someone has to track these objects and clean them up when they are no longer in use. This “someone” can either be the programmer who has to do manual memory management (those who have written code in C know what I mean), or the programming language runtime can automate this for you.
Python has automatic memory management. It uses a combination of reference counting and a generational garbage collector (GC). Reference counting is the primary mechanism of garbage collection, however, it doesn’t work when the references have cycles between them and for handling such cases it employs the GC.
In this post, we are going to cover both reference counting and garbage collection internals in CPython. However, I’ve already written about reference counting internals in quite detail in a past post, so the primary focus of this post is going to be on the garbage collector implementation. We will look at the core data structure definitions, algorithms, and the source code. Towards the end, we will also cover some of the major changes introduced in reference counting and garbage collection implementation as part of the GIL removal work.
If you prefer watching video, over reading text then you can check out my video on this topic as well:


A Short Primer on Reference Counting
If you have not read the reference counting article, let me give a quick recap.
What are References?
Whenever we create objects in our Python code, the CPython runtime allocates the object somewhere in memory and gives us back a reference to it. This means that the variables in our programs are essentially references to these objects.
As we assign the same object to other variables or pass to functions as arguments, the runtime increments the reference count of the object behind the scenes. At any point of time, the reference count of an object tells the runtime how many users of the object are there in the program.
Similarly, as any variable goes out of scope, the reference count of the corresponding object goes down by one. And when the object’s reference count reaches 0, it gets immediately deallocated.
It is a fairly simple idea, and very straightforward to implement as well. Let’s see how it is implemented.
Implementation Details behind Reference Counting
The first question is, where are these reference counts maintained by the runtime? Because each object has to have a reference count, it makes sense that the reference counts are maintained within the object’s memory itself.
The following figure shows the memory layout of a couple of CPython objects, the first one is a float object and the other is a complex type object.
 which contains the reference count, and the object body (pink region)")
The blue region in the object’s memory represents the object header, and the pink region represents its body where the actual data for the object is stored.
The header is where the reference counts are stored. The header consists of two fields:
The
ob_refcntfield which holds the object’s reference countThe
ob_typefield is a pointer to an object of typePyTypeObjectwhich holds all the type implementation details for that object, such as the type name and several function pointer tables. I’ve a detailed video on the type system internals of CPython where I discussPyTypeObject.
I would not go into more internal details than this about reference counting here. Suffice to say that when the runtime creates a new object it initializes the ob_refcnt field to 1 and it increments/decrements it depending on the situation.
After every decrement operation, the runtime checks if the value of ob_refcnt has reached 0, and if so, it immediately deallocates it. During deallocation, the runtime goes and decrements the reference counts of any objects contained within the object being deleted as well.
Limitations of Reference Counting
Reference counting is a very simple garbage collection technique. However, it doesn’t work in situations where the references end up in cycles with each other. In such situations, the reference count for the objects involved in the cycle never reaches 0, and as a result their memory is never released even if those objects are not being used anywhere.
Let’s understand with the help of an example. Consider the following figure.

In the top left part of the figure, we have a single linked list definition, and then we instantiate two nodes with their next fields pointing to each other, i.e., creating a cycle between them.
In the top right part, we can see the in memory view of these two node objects. Both the objects have a reference count of 2. One reference count is because of the variables node1 and node2, and the other reference is because of the next field of both the objects pointing to one another.
In the bottom left part of the figure we are deleting the node1 and node2 variables. As a result of this deletion, the reference count of both the Node object also goes down by 1 (as you can see in the bottom right side of the figure).
However, the objects still stay around because they each are holding references to each other and their reference count never goes to 0.
When we say `del node1` or `del node2` it doesn’t trigger decrement of reference count of its inner members. That would only happen when the object is being deallocated, and deallocation only happens when the reference count reaches 0.
To clean up such cyclic references, CPython uses a garbage collector (GC). Let’s talk about it.
CPython’s Garbage Collector
CPython implements a generational garbage collector, consisting of four generations: one young generation, two old generations and one permanent generations (where objects with static lifetime are kept, i.e., these objects are never meant to be cleaned up).
Understanding GC Generations
If you are not familiar with the concept of generations in a generational garbage collector, let’s understand it quickly.
A long-running and busy application can be creating a ton of objects every second. The garbage collector’s job is to track all these objects and figure out which ones need to be collected (cleaned up). The more objects the GC needs to scan, the higher the overhead.
However, the majority of objects are very short-lived; they are created, used, and discarded quickly. It makes sense to track such objects aggressively and clean them up frequently. This is the purpose of the young generation.
Newly created objects are initially assigned to the young generation. The GC runs more frequently to scan the objects in the young generation and clean them up. This process is known as a minor GC.
Any object that survives multiple minor GC cycles gets promoted to the old generation. The GC runs less frequently for the older generations, which makes sense because if an object did not die in the young generation, it is likely to live for a long time. Therefore, it doesn’t make sense for the GC to scan such objects frequently. This process, involving the old generation, is known as a major GC.
By segregating objects based on their lifespan and using different collection strategies for each generation, generational garbage collectors can optimize performance and reduce overhead.
Internal Representation of a GC Generation in CPython
Now that we know what generations are, let’s see how they are represented in the CPython code which will help us understand how objects are tracked for collection. The following listing shows the definition of the gc_generation struct:

A generation object contains a doubly linked list to track the objects for garbage collection. Apart from that, the count field maintains how many objects are part of that generation, and the threshold field dictates when the GC should run for that generation. For instance, for the young generation, the GC runs when the count of objects crosses the threshold.
Whenever a new object is created which needs to be tracked by the GC, it gets appended to the end of the doubly linked list of the young generation. However, this requires that the objects contain the next/prev pointers of the linked list so that they can be linked to a GC generation for tracking. This requires a change in the object layout, let’s discuss this.
Object Layout for GC Tracking
Primitive type objects such as ints, floats, strings are not tracked by the GC because these types cannot have reference cycles. Only the types which can contain other objects have the possibility of resulting in a cycle. Examples of such container types in Python are lists, dicts, sets, tuples, user defined classes etc.
In order to allow these objects to be tracked by the GC, they need to be added to the GC generation’s linked list. So, these objects need to maintain those next and prev pointers somewhere.
It doesn’t make sense to add these pointers in the body of the objects because every object will have different body definition, and the GC would not know where to find the pointers in the body.
It also doesn’t make sense to add these fields in the object header because not all objects are tracked by the GC, and it will be wasted memory space for such objects.
Therefore, for container type objects, there is an extra header which comes before the object header. This header contains the pointers to which the GC generation’s linked list can link. The following illustration shows the memory layout for such objects.

As you can see in this modified object layout, there is an extra header (the yellow region) before the object header (the blue region). This is called the GC header and it is only present for objects which are container types, and need to be tracked by the GC.
Next, let’s discuss how an object gets added to the young generation’s linked list on creation.
How Objects are Added to the GC
As an example, let’s see how a list type object is created and tracked by the GC. The following listing shows the code from CPython (I’ve removed some bits to keep it simple).

Let’s breakdown what is happening here:
The
PyList_Newfunction defined in Objects/listobject.c is called whenever we are creating a new list in our Python code.PyList_NewcallsPyObject_GC_Newto allocate memory for the new object. This function is used for allocating memory for all container type objects. It allocates memory for the object, as well as for the GC header where the linked list pointers are maintained.PyObject_GC_Newitself is a wrapper which eventually leads to the function_PyObject_GC_Newdefined in gc.c. The first thing it does is calculate how much total memory it needs to allocate by counting the GC header along with the object’s body size. It then callsgc_allocto allocate that memory.gc_allocallocates memory for the object and initializes the GC header fields toNULL. It then calls the_PyObject_GC_Linkfunction._PyObject_GC_Linkis a misleading name for the function considering what the function actually does. This function is extracting the young generation object from the GC state which itself lives inside the thread state object (read my article on CPython’s runtime internals to understand what all of these are). Then it increments the count of objects in the young generation, and if that count has surpassed the threshold, then it schedules the GC cycle.Scheduling the GC requires setting a flag in the
eval_breakerfield in the runtime state. The bytecode interpreter periodically checks theeval_breakerand runs GC if it notices that the flag is set (more on thiseval_breakermechanism below).Finally, once the object is created then
PyList_Newcalls_PyObject_GC_TRACK. This is where the actual tracking of the object starts. The object gets added to the end of the young generation’s linked list. You should be able recognize the usual linked list pointer manipulations in that function.
How a GC Cycle is Scheduled for Different Generations?
In the previous section we briefly saw how the GC cycle is scheduled, but let’s discuss it in more detail.
When a new container type object is created, it is added to the young generation’s list of GC objects and the generation’s object count is incremented. The young generation has a configurable threshold, and when the number of objects in it crosses that threshold, it schedules the GC.

During every GC cycle, the objects which survive the young generation clean up, get moved to the next old generation.
In the previous CPython versions, the older generations used to also run based on a configurable threshold, e.g., clean up the medium generation when the young generation has been cleaned x number of times.
But, recently this has changed and now on every cycle, the GC also incrementally cleans up a small part of the oldest generation as well. This is called incremental GC (more details in this GitHub PR).
When the GC Cycle is actually triggered?
Scheduling the GC cycle doesn’t mean it will run immediately. Let’s understand what happens during GC scheduling and when the actual cycle run happens.
The Python code executes on the interpreter in the context of an OS thread, and the runtime maintains the information about the thread’s state in an object called thread state. The thread state contains information about the code executing on the interpreter in the context of that thread, such as the stackframe pointer, the GC state, and the eval_breaker.
eval_breaker is a collection of flags to track the pending async tasks that the interpreter needs to handle, such as handling signals, async exceptions, and GC triggers. We already saw how it is used for scheduling the GC cycle.
The following listing shows the definition of the thread state struct.

The interpreter checks eval_breaker at the beginning or the end of some specific bytecode instructions, such as function calls, and jump instructions. The following snippet shows the code for handling the RESUME instruction, and you can see the call to check the eval_breaker towards the end of it.

And if any of the flags are set in eval_breaker then CHECK_EVAL_BREAKER leads to a call to _Py_HandlePending.

Within _PyHandlePending, the interpreter suspends any other activity in that thread, and systematically checks the presence of different async event flags. For each flag present, it handles the corresponding event. The following listing shows the code for _Py_HandlePending:

In the listing I’ve highlighted the part where the interpreter handles the GC event. It calls the function _Py_RunGC which is the entry point to the garbage collector implementation (gc.c). This is also our cue to dive into the GC internals next.
The GC Entry Point
The interpreter calls the _Py_RunGC function to trigger a GC cycle. The following listing shows what happens inside it:

As you might know, you can enable/disable GC in an interpreter. So _Py_RunGC does nothing if the GC is disabled for the interpreter. Otherwise it calls _PyGC_Collect.
_PyGC_Collect (shown above) extracts the GC state object from the thread state and makes sure that another GC cycle is not in progress. It then checks the value of the generation argument and based on that triggers the right cycle. In this case, _Py_RunGC passes the value 1 for generation, which results in an incremental GC cycle run (which means collect the young generation and parts of the oldest generation). To trigger this incremental GC cycle, it calls gc_collect_increment.
I’m not going to show the code for gc_collect_increment, but it simply builds a list of objects from the young generation and one of the older generations that should be scanned and then it calls gc_collect_region which is the main GC function. Let’s look at it in detail.
The Core GC Function
The following listing shows and anntates the gc_collect_region function which contains the main logic of the GC in CPython (I’ve removed some extra book keeping stuff and asserts to cut down its length).
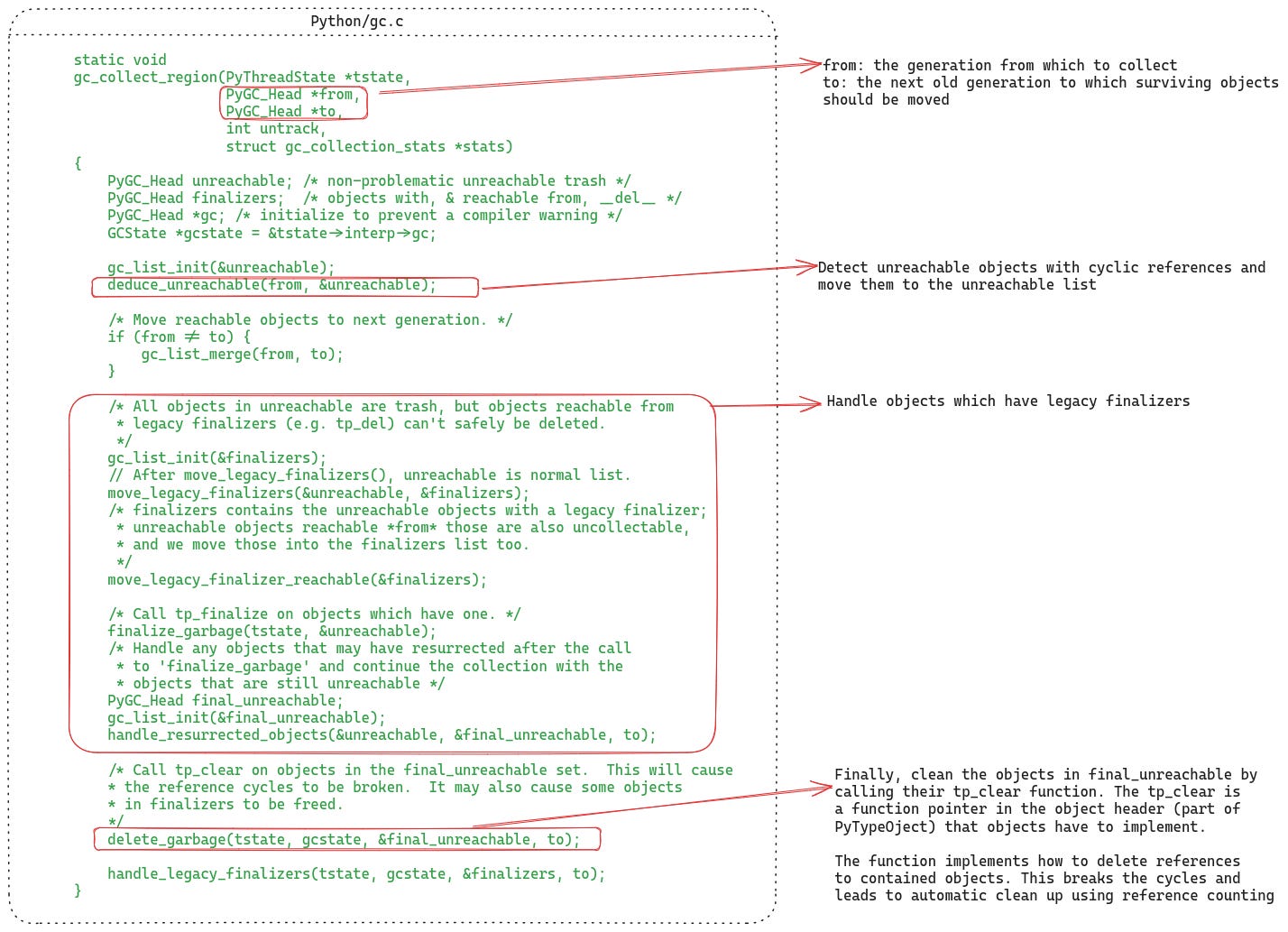
The function works in three steps:
First, it identifies the unreachable objects that have cyclic references
Then, it handles the unreachable objects which may have legacy finalizers. The comments explain pretty much everything.
Finally, it calls
delete_garbageand passes it the final unreachable list of objects.delete_garbageiterates through this list and for each object it calls itstp_clearfunction. Every container type object implements thistp_clearfunction, and in this function it defines how to decrement the reference count of each of the objects that it contains. Decrementing the reference counts breaks the reference cycles, and triggers the automatic deallocation using the reference counting mechanism. For instance, the following listing shows the list object’s implementation oftp_clearfunction (see this article to read about the internals of the list object in CPython).
Implementation of tp_clear by the list object in CPython

The meat of this whole process is the first step which finds objects with cyclic references that are unreachable from anywhere else. Let’s understand how that works, but before we look at the code, we need to understand the algorithm.
The Cycle Detection Algorithm
We know that the job of the GC is to find unreachable objects, i.e. objects which do not have any references anymore, and clean them up. However, in CPython such objects are already cleaned up by the reference counting mechanism. The GC in CPython is specifically required to find objects which may have cyclic references and clean them up if they are not reachable from outside that cycle. The meat of this implementation is the cycle detection algorithm.
Let’s understand how the GC detects cycles using an example. Consider the following code snippet which defines a linked list and creates 3 nodes with cycle between them.

If we want to visualize these objects, this is how they would look like in memory:

Notice the following details:
link3is at the head of the GC’s linked list because that was the first object we created, and as a result it would be at the beginning of the linked list.link2andlink3have reference count value 1 (see theob_refcntfield) whilelink1has reference count 2 because it has an external reference from variableAas well.link1,link2, andlink3are the only objects that the GC needs to examine.
The algorithm runs in three steps. Let’s walk through each of them.
Step-1: Initializing gc_refs
The first thing that the GC does is to go through each object in the GC list and initialize the gc_refs field to the same value as ob_refcnt.
gc_refs is a temporary field that the GC uses to do accounting of the reference counts to figure out if there is a cycle or not. As this is a temporary field, the GC implementation repurposes some of the spare bits in the _gc_prev field in the GC header to store this value. Once the GC cycle finishes, those bits are cleared.
This is how the state of the GC list would look like after this step:

Step-2: Subtract gc_refs
The next step is to traverse the references between the objects and decrement gc_refs for each incoming internal reference that an object has.
To do this, the GC visits every object in its list. For each object, it traverses each of its contained references. For each contained reference, if the object it points to is part of the GC list, then the algorithm decrements that object’s gc_refs by 1 to account for the internal reference.
In our example the GC would start at link3, and link3 contains a reference to link1. So the GC would decrement link1’s gc_refs by 1. The following illustration shows this.
tp_traverse()is a function pointer defined inPyTypeObjectthat every type implements. It defines how to visit all the members of that object. This function also takes a callback function pointer as an argument that gets called on visit to each member.

Next, the GC would visit link2 and link1 (in that order) and repeat the same process for both of them.


At the end of this whole traversal, the GC would eliminate the source of internal references between the objects. If the only references an object had were from within that cycle, then at the end of this step that object’s gc_refs would reach 0.
On the other hand, an object with a non-zero value for gc_refs means it is reachable from outside. In this case, link1’s gc_refs is 1 because it is also reachable from the variable A.
Step-3: Detecting Unreachables
Having gc_refs 0 doesn’t really mean that the object is not reachable from outside. It’s possible that the object has an internal reference from another object which is reachable from outside. In our example, link2 and link3 have gc_refs 0, but they are reachable from link1 which is reachable from the variable A. Thus, there is one more step in the algorithm to detect the actual unreachables.
This is the final part of the cycle detection where the objects in the GC list are split into reachables and unreachables and the unreachable list is cleaned up.
The algorithm starts with two lists: the reachables and the unreachables. Initially, all the objects are part of the reachables list, and the unreachables list is empty.
Then the algorithm proceeds as follows:
For each object in reachable list
If object’s gc_refs == 0:
Move it to unreachable (tentatively)
Else:
Use tp_traverse to visit all of its members
If member is part of the unreachable list:
Move it back to the reachable list
Set member.gc_refs = 1 to mark it reachable
Else if member.gc_refs == 0:
Set member’s gc_refs = 1 to mark it as reachable
Else:
Nothing to doAt the end of this algorithm, we would know which objects with cyclic references are unreachable and can be cleaned up. Let’s understand how this would work for our example scenario.
The GC would start at the head of the linked list, which is link3. As link3’s gc_refs is 0, it would get moved to the unreachable list.

Next, the GC would visit link2 and because it also has gc_refs 0, it would also end up in the unreachable list.

Next, the GC would visit link1 but its gc_refs is non-zero. According to the algorithm, the GC needs to visit all of its members and do some analysis for each of them.
For link1, the only member reference is to link2. Now, link2 at this point is in the unreachable list. So according to the algorithm, it has to be moved back to the end of the reachable list with its gc_refs value set to 1.

At this point, the GC had visited all the objects in the initial reachable list, but link2 got appended towards the end, and as a result the GC needs to revisit it.
This time link2’s gc_refs is 1 and therefore the GC would have to visit its member link3 now. Because link3 is in the unreachable list, it would get moved back to the reachable list with gc_refs set to 1.

Finally, link3 is at the end of the reachable list and the GC will visit it again. This time its gc_refs is 1. The GC would visit link3’s only member: link1. Because link1’s gc_refs is != 0, the GC has nothing to do.

At this point the GC would stop because it has reached the tail of the reachable list.
We can see that at the end of the algorithm, the unreachable list is empty which means there were no objects with cycles which were unreachable from outside.
If link1 did not have a reference from the variable A, then the picture would have been reversed. All the objects would have ended up in the unreachable list and deallocated. I encourage you to step through the algorithm for that scenario and verify for yourself.
Source Code Reference
I will not do a walkthrough of the complete GC code because it’s pretty large and has many tedious details. However, the above cycle detection discussion can easily be mapped to this function in gc.c which forms the meat of what the GC does.

Changes in Memory Management Internals Due to GIL Removal
The GIL (Global Interpreter Lock) removal work is in full steam in CPython and you can already disable the GIL in the 3.13 release. One of the biggest areas which is affected by the removal of the GIL is memory management. I won’t go into a lot of technical details here but I want to highlight what has changed.
Introduction of Biased Reference Counting
The reference counting mechanism that we discussed is not thread safe. It was built under the assumption of the GIL, i.e., at any point of time, only one thread is ever running, and therefore an object’s reference count could only be modified by one thread.
However, in the absence of the GIL, it is prone to race conditions. To mitigate this, the reference counting implementation has been changed to biased reference counting.
In the biased reference counting scheme, every object maintains two reference counts. One is the local reference count, and the other is a shared reference count.
The local reference count is only modified by the owner thread (the thread which created that object) without any synchronization, while the shared reference count is modified by all the other threads using atomic instructions. Periodically these reference counts are merged to get the actual reference count of the object.
The underlying idea is that most objects are ever modified by only the owner thread, and there should be a fast path for that thread to access or modify reference counts. While other threads can use a slower path.
Changes in the GC Implementation
Even though the underlying logic behind the GC is the same in the NOGIL implementation of the GC, there are quite a few fundamental changes to make it thread-safe.
GC Pauses
The original GC ran under the GIL and had no concerns about the objects being modified by the other threads while the GC was running (the GC thread would not release the GIL while it was not done).
However, that is not true for the NOGIL world. As a result one of the things this GC implementation does is stop-the-world pauses where no other thread can run during the GC cycle.
Non-generational GC
The new GC implementation does not have any generations, this means that the GC scans all the objects on the heap in every cycle.
The concept of generation makes sense in languages where GC is the only mechanism to clean up memory. Usually most objects are short-lived and they end up in the young generation. The GC runs frequently for the young generation to clean it up.
However, in CPython most of the short-lived objects are already cleaned up by reference counting. So having the complexity of generations doesn’t give that much of a benefit.
The other advantage is that a non-generational GC is much simpler to make thread-safe.
Using mimalloc for tracking objects
Finally, the NOGIL implementation uses the mimalloc memory allocator library because it’s thread-safe.
And the GC takes advantage of the mimalloc’s facilities to track the objects, instead of maintaining a dedicated linked list like the original GC implementation.
Source Reference
There is no time or space to go into more implementation details of the new thread-safe GC in this article, but if you wish you can read its source in Python/gc_free_threading.c.
Summary
We’ve reached the end of this encyclopedic coverage of the garbage collector implementation in CPython. We covered all the details behind it, let’s do a quick summary and end this article.
CPython uses reference counting as the primary mechanism for memory management.
But, reference counting doesn’t work when there are cyclic references between objects.
To handle such edge cases CPython also implements a garbage collector.
The GC implementation is a traditional generational GC split into 4 generations: 1 young gen, 2 old gens and 1 permanent gen.
On creation, objets get added to the young gen. The GC is triggered for the young gen when the count of objects in it crosses a configurable threshold.
The GC runs through the young gen, and finds objects with cyclic references which are unreachable from anywhere outside and cleans them up.
The surviving objects are moved up to the old generation.
The GC runs less frequently for the old generations.
There are many changes in the memory management implementation to make it thread-safe in the absence of the GIL.
Reference counting implementation is changed to biased reference counting which is thread-safe, yet performant.
The GC has many changes:
Switch from generational GC to non-generational GC
Using mimalloc library for tracking objects
Addition of stop-the-world pauses during GC cycles to stop other threads from modifying objects
Underlying cycle detection algorithm still remains the same as the old GC
Support Confessions of a Code Addict
If you find my work interesting and valuable, you can support me by opting for a paid subscription (it’s $6 monthly/$60 annual). As a bonus you get access to monthly live sessions, and all the past recordings.
Many people report failed payments, or don’t want a recurring subscription. For that I also have a buymeacoffee page. Where you can buy me coffees or become a member. I will upgrade you to a paid subscription for the equivalent duration here.
I also have a GitHub Sponsor page. You will get a sponsorship badge, and also a complementary paid subscription here.
Are you on Windows? On my Linux x86_64 machine `Py_ssize_t` is `8` bytes (not 4) and `void*` is `8`. Therefore *`ob_refcnt` is `8`* either way:
```c
// from object.h
struct _object { // typedef _object PyObject; in pytypedefs.h
__extension__
union {
Py_ssize_t ob_refcnt;
#if SIZEOF_VOID_P > 4
PY_UINT32_T ob_refcnt_split[2];
#endif
};
PyTypeObject *ob_type;
};
```
https://github.com/python/cpython/blob/42351c3b9a357ec67135b30ed41f59e6f306ac52/Include/object.h#L110-L134
```python
assert ctypes.sizeof(ctypes.c_void_p) == 8
assert ctypes.sizeof(ctypes.c_ssize_t) == 8
```