

Are Function Calls Still Slow in Python? An Analysis of Recent Optimizations in CPython
How costly it is to call functions and builtins in your python code? Does inlining help? How have the recent CPython releases improved performance in these areas?

I came across this viral post on X/Twitter where Pritam found that his Leetcode solution was slower when he was using Python’s min built-in function and the performance improved when he implemented min inline in his Python code.
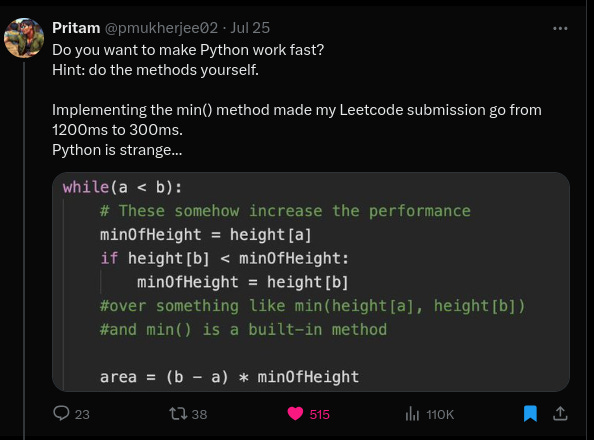
It’s true that function calls can be costly, they are known to be even more costly in interpreted languages such as Python. And the usual recommendation has been to inline your functions if they are part of the bottleneck.
The OP in this screenshot was using Python 2 which is an ancient history at this point of time. But Python 3 has been through multiple releases in the last decade and the last few releases have been very focused on improving the performance of the language. So is it still true that function calls are expensive in Python?
I was curious so I created 3 microbenchmarks to measure three things:
What is the impact of calling a built-in in a loop
What is the impact of calling a Python function in a loop
And what is the impact of inlining that function in the loop
Unsurprisingly, the results show that the performance of CPython has improved significantly in all the three areas with the recent releases.
In this post I am going to discuss the specific improvements introduced in CPython which help improve the performance of the interpreter. I am going to explain why things were slow previously and how the new change helps with that. Let’s dive in.
Outline of the Article
We will go over the three benchmarks one by one. For each benchmark we will look at the code, see the performance numbers across CPython releases and then discuss the specific optimization introduced in CPython which have led to the improvement across the releases.
Upcoming Live Session
Live Session: Live Coding a Bytecode Interpreter for Python

We are due for our next live session. The previous session on performance engineering was quite a success. Those who attended, left some amazing feedback. Now it’s time for the next one.
Benchmark 1: Measuring the Overhead of Executing Simple Instructions in a Loop
Let’s start with the first benchmark where we are doing some simple computation inside a loop, such as computing a min from a list. The code is shown below. It uses a while loop instead of a more Pythonic for loop because the original code in the Twitter post was using a while loop and I wanted to stick to that.
def benchmark1(heights):
a = 1
b = len(heights) - 1
min_height = heights[0]
while a < b:
if heights[a] < min_height:
min_height = heights[a]
a += 1
return min_height
Following are the performance numbers for this benchmark for last few CPython versions:

This benchmark is simply measuring the overhead of simple computation such as comparing two integers inside a loop. As we can see the interpreter has gotten significantly better at doing this with the recent releases. Now let’s discuss what internal optimizations are responsible for this.
Introduction of Super Instructions
One of the simple optimizations introduced in CPython was that of super instructions. These are special bytecode instructions that are generated by fusing together two consecutive instructions of specific types which tend to occur in pairs in programs. Let’s understand how it works in the context of this specific benchmark.
The image below shows the bytecode for the loop body of this benchmark for Python 3.14.0a0 (left) and Python 3.10 (right). In the loop the interpreter needs to repeatedly load the heights[a] and min_height values onto the stack before it can compare them. For loading these values onto the stack the interpreter executes the LOAD_FAST instruction.

We can see a clear difference between the bytecode for the two Python versions. The 3.10 version contains two consecutive LOAD_FAST instructions, while the 3.14 version contains a single LOAD_FAST_LOAD_FAST instruction.
This is an example of a super instruction. It is generated by the compiler during an optimization pass after it generates the initial bytecode for the program. The following figure shows the code for this optimization in CPython, it was introduced during the 3.13 release.

Benefits of Super Instruction Optimization
The main benefit of this optimization is that it reduces the amount of work done by the interpreter. Interpreting every instruction requires fetching the next opcode, decoding it, and then jumping to the code where the implementation of that bytecode is present. This is a small amount of overhead but inside a hot loop everything magnifies.
Additionally, this also helps the CPU execute the interpreter loop efficiently. Having fewer bytecode instructions in the interpreter means fewer jumps for the CPU as well. Having fewer jumps in a tight loop results in improved instruction cache locality, and better usage of the branch predictor because the freed up branch table entries could be used for other branches.
Moreover, the implementation of the LOAD_FAST_LOAD_FAST instruction in the interpreter provides the CPU with an opportunity to increase its instruction throughput. Modern CPUs can process multiple instructions in parallel, a capability known as instruction-level parallelism, provided there are enough independent instructions available. In the case of LOAD_FAST_LOAD_FAST, its implementation contains several instructions that are independent of each other, allowing them to be executed concurrently.

Bytecode Instruction Specialization
The 2nd optimization which is massively helping the performance for this benchmark is instruction specialization introduced in CPython 3.12 release.
If you look at the bytecode from the previous section again, you should notice that the interpreter needs to repeatedly execute the COMPARE_OP and BINARY_OP for doing comparison and increment operations inside the loop.
These instructions are relatively expensive to execute because they involve dynamic dispatch. I’ve discussed what exactly goes on behind the scenes here in my article “How Many Lines of C it Takes to Execute a + b in Python?“. But let me give the summary.
When the interpreter needs to handle instructions such as BINARY_OP or COMPARE_OP, it receives the operands on the stack. The interpreter is unaware of the concrete types of these operand objects, whether they are ints, strings, floats or something else, and as a result it does not know how to handle this specific operation for the operands at hand. The interpreter figures out how to handle the operation by doing a function pointer lookup inside the operand objects. But it involves a massive amount of pointer chasing.
The interpreter first needs to dereference the operand object
Next, it needs to dereference the pointer to the PyTypeObject field (ob_type) which contains the function pointer tables
Then the interpreter needs to dereference the function pointer table and lookup the function pointer
Finally, it needs to dereference the function pointer itself to call the function.
The following figure illustrates this pointer chasing.

This level of indirection is bad at the CPU level because all of these pointer dereferences are dependent memory loads. It means that the CPU needs to wait for the first load to finish before it can proceed with the next. It reduces the instruction throughput, and if any of those loads have a cache miss, it can cause a long stall of hundreds of cycles until the data arrives from the main memory.
But thanks to instruction specialization, the slow BINARY_OP and COMPARE_OP instructions are converted to specialized instructions such as BINARY_ADD_INT where the add operation is done directly in the interpreter without doing any pointer lookups.
Benchmark 2: Measuring the Cost of Calling a Built-in
This is a slight variation of the previous benchmark. Here instead of doing the min computation ourselves, we are calling the built-in min function. The code for this benchmark is below:
def benchmark2(heights):
a = 1
b = len(heights) - 1
min_height = heights[0]
while a < b:
min_height = min(heights[a], min_height)
a += 1
return min_height
This benchmark is measuring the overhead involved in calling a built-in function. The following table shows the improvement in CPython’s performance for this across releases.
There have been two changes which can be attributed to the improvement of this version from 17.33 seconds in Python 3.10 to 6.7 seconds in Python 3.14.0a0. Let’s discuss those.
Loading Globals Faster
Let’s take a look at the bytecode for the code of this benchmark.

When executing this, the interpreter needs to load the min() built-in function onto the stack. For doing that it executes the LOAD_GLOBAL instruction.
The LOAD_GLOBAL instruction needs to lookup the named global object in two dictionaries. The first dictionary contains all the globals in the current scope, and the second contains all the builtins.
Dictionary lookups are fast but they are not free. Again, thanks to instruction specialization the interpreter optimizes this into a specialized instruction: LOAD_GLOBAL_BUILTIN.
The specialized instruction caches the index of the object in the builtins dictionary. It avoids the entire dictionary lookup process and simply returns the object at the cached index value. The following figure shows how the interpreter implements this instruction.

Optimization of the min and max Builtins
But the specialization of LOAD_GLOBAL into LOAD_GLOBAL_BUILTIN is not the main contributor to the impressive improvement of this benchmark. The real reason is a specific optimization applied to the min and max builtins.
There are two calling conventions inside the interpreter for calling functions, one is the old convention called tp_call and the other is vectorcall.
When using tp_call, intermediate tuples and dictionaries are created for passing the function arguments and there might be overhead of other intermediate objects as well (more details described in the PEP 0590). In the vectorcall convention, the arguments are passed as part of a vector which eliminates a lot of the intermediate object creation.
Before the CPython 3.13 release, the min and max builtins were being called using the tp_call convention. This meant that calling these inside a hot loop would allocate and deallocate a ton of intermediate objects. By switching to the vectorcall convention the performance of these builtins has been reported to improve by upto 200%, and even in this benchmark it shows an improvement of more than 150%.
You can read the PR of this change here for more context.
Benchmark 3: Measuring the Overhead of a Python Function Call
Finally, let’s discuss what changes are behind the performance improvements of the 3rd benchmark which implements min as a Python function and calls it from inside the loop. The code is shown below.
def pymin(a, b):
if a <= b:
return a
return b
def benchmark3(heights):
a = 1
b = len(heights) - 1
min_height = heights[0]
while a < b:
min_height = pymin(heights[a], min_height)
a += 1
return min_height
The following table shows the performance of different CPython releases for this benchmark:
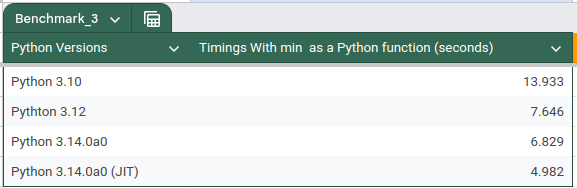
As per the numbers in the table for this benchmark version, the performance improved significantly from 3.10 to 3.12 and then marginally for 3.14.0a0.
This benchmark is essentially measuring the overhead involved in executing a python to python function call (because both the caller and callee are implemented in Python).
Until Python 3.11 the way Python to Python function calls were handled in the interpreter was convoluted and expensive, it involved the interpreter invoking itself recursively for handling each such function call. This recursion got inlined in CPython 3.11 release, leading to significant performance improvements. Let’s understand it in detail.
Inline Execution of Python-to-Python Function Calls
The interpreter starts the execution of a Python program from the program’s main function. This is done by first setting up the stackframe for the main function and then invoking the interpreter. The entry point of the interpreter is the function _PyEval_EvalFrameDefault defined in ceval.c.
What is a stackframe? Execution of every function in your code requires a corresponding stackframe. The stackframe contains the locals and globals of that function, the compiled bytecode, instruction pointer etc which help the interpreter execute the code. For more details you can watch the recording of my talk on CPython Virtual Machine Internals which covers how the virtual machine is implemented in CPython.
The _PyEval_EvalFrameDefault function contains a giant switch case for handling all the bytecode instructions supported by the interpreter. The function iterates through the instructions of the given function and executes the corresponding switch case.

When you call another function in your Python code, it results in the CALL bytecode instruction being generated. When the interpreter encounters a CALL instruction, things get interesting.
In CPython 3.10 and earlier, the CALL instruction used to create a new interpreter stackframe for the function being called and then it used to recursively reenter the interpreter by calling its entry point _PyEval_EvalFrameDefault.
This was bad for performance from many angles at the hardware level. The recursive call into the interpreter required saving the registers for the current function, and pushing a new C stackframe. It would lead to increased memory usage because each recursive interpreter call would allocate its own local variables on the stack, and other heap allocations. Apart from that it would also lead to poor instruction cache locality due to the constant jumps in and out of the bytecode evaluation loop.
In the 3.11 release this was fixed by eliminating the recursive call to the interpreter. Now the CALL instruction simply creates the stackframe for the called function, after that it immediately starts evaluating the new function’s bytecode without ever leaving the loop.
Note: Your code may be calling a function which is implemented in C, or it could be calling a function written in Python. The above discussion is about a Python function call. In the case of a C function call the interpreter never needed to do all the gymnastics discussed above.
You can read the discussion behind this change in the CPython bug tracker.
Specialization of the CALL Instruction
While most of the improvement seen in the performance of this benchmark is due to the inlining described above, there is another minor improvement related to function call execution in the interpreter. It is the specialization of the CALL instruction.
The CALL instruction is a generic instruction for executing all kinds of callables. When handling it, the interpreter needs to check the type of the callable, such as whether it is a class method, instance method, a function or something else, and based on that it needs to invoke the callable in the right manner.
The specialization of this instruction saves all of this extra work for the interpreter and inside a tight loop it might help improve the performance.
Summary
In this article, we’ve dug into the nitty-gritty of Python performance, specifically looking at the cost of function calls, built-in calls and inlining code in a hot loop. We saw how recent tweaks in CPython have made things faster. Our benchmarks showed some solid performance boosts from Python 3.10 to Python 3.14.0a0. Here’s a quick rundown of what’s behind those gains:
Super Instructions: By merging back-to-back bytecode instructions into single “super” instructions like
LOAD_FAST_LOAD_FAST, CPython cuts down on the overhead of running individual bytecode instructions. This boost helps both the interpreter and the CPU run more efficiently.Bytecode Instruction Specialization: New specialized bytecode instructions (like
BINARY_ADD_INT) remove the need for slow, dynamic dispatch, speeding up everyday operations.Optimization of Builtins: Switching from the older
tp_callmethod to the fastervectorcallhas given a big performance push to theminandmaxbuiltins.Inlining Python-to-Python Function Calls: By getting rid of the old way of handling Python-to-Python function calls (which involved cumbersome recursive interpreter calls), newer versions like CPython 3.11 make these function calls faster and smoother.
Overall, these changes show Python’s ongoing effort to get faster and more efficient. But before taking any of the findings from these articles and applying to your code, remember to first profile and measure to find the slowest paths (Amdahl's law).
References and Resources
Support Confessions of a Code Addict
If you find my work interesting and valuable, you can support me by opting for a paid subscription (it’s $6 monthly/$60 annual). As a bonus you get access to monthly live sessions, and all the past recordings.
Many people report failed payments, or don’t want a recurring subscription. For that I also have a buymeacoffee page. Where you can buy me coffees or become a member. I will upgrade you to a paid subscription for the equivalent duration here.
I also have a GitHub Sponsor page. You will get a sponsorship badge, and also a complementary paid subscription here.
I don't see why b = len(heights) - 1 rather than b =len(heights) . Doesn't that end up skipping the last element of heights given the strict inequality in the while-loop? Doesn't affect the quality of the benchmarking, to be sure.