

Speculative Decoding and Beyond: A Survey of Speculative Decoding Techniques
What is speculative decoding, how it works and what are some of the recent advances in this area?

Doing inference using LLMs in production is not easy, it requires massive compute and as a result it can get expensive pretty quickly. This has led to the development of several techniques to make the inference more cost and compute efficient. One such technique that has emerged in the last couple of years is speculative decoding. When doing inference on LLMs, one full forward pass of the model results in the generation of a single token. This is a highly inefficient use of the available compute resources of the GPU or the accelerator chip, and speculative decoding solves this by enabling the prediction of multiple tokens in a single forward pass.
It originally appeared in an ICML paper in 2023 and since then it has been adapted and deployed widely. It has also seen various modifications which have reduced the cost of its implementation as well as improved its accuracy.
This article is a survey of speculative decoding techniques. We will first discuss the original speculative decoding technique as proposed in the ICML 2023 paper. After that we will discuss the Medusa architecture which simplifies the implementation of speculative decoding while improving the performance. Finally, we will close by looking at some proposed modifications to Medusa which address some of the drawbacks in its architecture.

Simplify GenAI Deployment and Achieve Ultra-Fast Inference with Simplismart (Sponsored)
While we're on the topic of LLM inference optimization, there's an exciting startup I'd like to highlight: Simplismart.ai. They're tackling not just inference, but the entire pipeline of fine-tuning and deploying open-source AI models, whether in the cloud or on-premises.
With their Terraform-like declarative language, Simplismart.ai ensures seamless, uniform, and error-free model deployment. With built-in model observability, they provide instant insights into model performance.
But all of that is worth nothing if we're left reeling from astronomical cloud bills. To tackle this, they have built an ultra-optimized inference engine capable of extremely high throughput while being cost-effective. I’ve seen their internal benchmark numbers, and they look mighty impressive.
With a fresh $7M in funding, Simplismart is poised for growth. If you’re looking to streamline your deployment and cut down inference costs, I highly recommend giving them a look!
Underlying Inefficiencies in LLM Inference
Let’s first understand the inefficiencies involved in doing LLM inference. Typically you need a large GPU to do the inference. As these LLMs are deep neural network models, the inference involves doing a forward pass of the model using the context vector as the input.
To perform the inference, the weights of the model need to be moved from the high bandwidth memory (HBM) of the GPU into the accelerator. A single inference results in the generation of a single token and in order to generate a large number of tokens, multiple such forward passes need to be performed and in each pass the weights need to be moved from the HBM to the accelerator chip. This makes the whole inference process bottlenecked on memory as opposed to compute, because even though the GPU has compute capacity to generate several tokens, that compute is not being fully utilized.
It would be prudent if once the weights are moved into the accelerator, multiple tokens could be predicted in parallel so that the available GPU compute was maximally utilized. However, the autoregressive nature of the LLM architecture prohibits this from happening because at every step of the next token generation, the model needs the previously generated tokens as part of its context.
This leads us to speculative decoding which solves the problem of generating multiple tokens at each inference step without requiring any change in the underlying architecture of LLMs.
The Inspiration Behind Speculative Decoding
The underlying motivation behind speculative decoding is to improve the GPU resource utilization and in the process improve LLM inference throughput by predicting multiple tokens in parallel.
This is inspired by the concept of speculative execution in traditional processors (CPUs). These processors also have several execution resources but if the processor only executes one instruction at a time, those resources remain unutilized. So the processor tries to execute multiple instructions in parallel. And, in order to do that sometimes the processor needs to speculate which set of instructions it needs to execute because there might be branches in the code and only one of those can be taken (think of if/else or switch cases). The processor predicts the branching direction and speculatively executes instructions in that branch. If the prediction was right, then the resource utilization is improved, and the instruction throughput is also high, which results in faster execution of the program. However, if the prediction was wrong, it results in wasted work.
Now, let’s talk about how speculative decoding works as proposed in the original ICML 2023 paper.
The Mechanics of Speculative Decoding
The speculative decoding paper proposes the use of a smaller more compute efficient model for predicting the next few tokens. This smaller model is called the speculator model, but you may also see it being referred to as the draft model in some places.
There is no restriction on the choice of this speculator model, it can have any architecture and any number of parameters. However, in the paper they only chose models of the same architecture as the base LLM, but fewer parameters. For instance, they performed an experiment using LaMDA-137B as the base model and LaMDA-100M as the speculator on a dialogue task.
Let’s talk about the process of speculative decoding. We will consider a simplified example of speculatively predicting just the next one token to understand what all goes on and then we can generalize it to predicting next k tokens.
As the speculator model is also an autoregressive model here, to predict the next token it is fed the current prefix as input. The prefix here is the context vector plus any set of additional tokens that were generated previously. The speculator produces the next token x1.
After the speculator has finished its job, it is time to verify the tokens it has generated using the base LLM. Verification here simply means that whether the speculated next token is something that the base LLM would have also produced given the same prefix as context. To do this, the same prefix is fed to the base LLM and the next token is predicted. If the probability of the token as generated by the speculator is less than or equal to the probability of the same token as generated by the base LLM, then it is accepted, otherwise it is rejected. The intuition being that we don’t want to accept any token that the speculator generates with high probability but the base LLM is highly unlikely to produce that token.
While the base LLM is predicting and verifying the next token x1, another inference is invoked on it in parallel using
[prefix + x1]as its input to produce the next token x2. This is speculative work, assuming that x1 will be accepted. If eventually x1 is not accepted, then x2 is also discarded, and the right token will be picked up from the first inference done on the base LLM to verify x1. On the other hand, if x1 is accepted, then we have speculatively generated the next two tokens x1, and x2 in the time in which we would have normally generated only one token.
The following diagram illustrates this process visually with an example prefix of “the quick brown fox”.
![Illustration of how speculative decoding works for speculatively predicting and verifying a single future token. The speculator predicts the next token using the current prefix as input. Then, the base LLM takes the same input and produces its output. At the same time, the base LLM does a parallel inference using [prefix + x1] as input to speculatively predict the next token. If base LLM accepts the speculator’s prediction then two tokens are produced. Otherwise, the correct token is picked up from the base LLM’s first inference.](https://substackcdn.com/image/fetch/$s_!ckwS!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F2b48e1ee-25eb-4cd6-9946-1b66c432b0dc_1351x1150.png "Illustration of how speculative decoding works for speculatively predicting and verifying a single future token. The speculator predicts the next token using the current prefix as input. Then, the base LLM takes the same input and produces its output. At the same time, the base LLM does a parallel inference using [prefix + x1] as input to speculatively predict the next token. If base LLM accepts the speculator’s prediction then two tokens are produced. Otherwise, the correct token is picked up from the base LLM’s first inference.")
This same process can be generalized to speculatively predict the next k tokens. The speculator model is initially fed the prefix to generate the next token x1. Then it is fed [prefix + x1] to produce x2, and this is repeated until the next k tokens are generated.
Then k parallel inferences are invoked on the base LLM. The first inference is done using the [prefix] as input and is used to verify x1. The 2nd parallel inference is done using [prefix + x1] as input to verify x2, and so on. It is very likely that only the first few of these k tokens will be accepted. If the first m tokens are accepted, then we can pick up the base LLM’s prediction for m+1th token, and overall we would have produced m+1 token in parallel. This is the whole idea of speculative decoding.
The Medusa Architecture for Speculative Decoding
Although the scheme as laid out in the original speculative decoding paper is effective, it has some limitations. For instance, it requires picking up an appropriate speculator model and then integrating it with the base LLM to do the speculation. The speculator model also requires pre-training to align its predictions with the base model, so that a higher number of speculatively predicted tokens are accepted. Apart from that, the speculator model also does one token prediction at a time, whereas a speculator capable of generating multiple tokens can result in even better resource utilization and higher token throughput. This was the motivation behind the Medusa architecture for doing speculative decoding introduced in the 2024 ICML paper.
Instead of using a separate speculator model, the Medusa paper proposes adding multiple prediction heads on top of the base LLM. These prediction heads are added in the form of a single feed forward layer on top of the last hidden layer in the base LLM.
If there are k prediction heads, the prediction head at the first position predicts the next token, the prediction head at the second position predicts the token after that, and similarly, the prediction head at the kth position predicts the token k steps ahead.
The following illustration from the Medusa paper shows the architecture in action. It shows three prediction heads appended to the last hidden state of the base model. The three heads predict the next three tokens. Head 1 predicts the immediate next token, head 2 predicts the subsequent token and the last head predicts the third next token. Each head produces multiple predictions out of which top-k are selected based on some sampling criteria.

Fine Tuning of the Medusa Prediction Heads
Before the prediction heads can be used for doing speculative prediction of tokens, they need to be fine tuned so that their predictions match that of the underlying base model. The Medusa paper proposes two ways of doing this fine tuning and they call these models as Medusa-1 and Medusa-2 in the paper.
Medusa-1: Freeze the Base Model
The simplest way to fine tune the prediction heads is by freezing the layers of the underlying base model and minimizing the cross-entropy loss of the Medusa prediction heads on a fine tuning dataset. The paper suggests that the fine tuning dataset should align with the base model’s output distribution, and they even say that it is fine to use the same fine tuning dataset as for the base model.
The fine tuning process involves, doing predictions using the Medusa heads, and minimizing a cross-entropy loss between the predictions and the ground truth token.
The paper also notes that this fine tuning process is very light weight and can be done on a single consumer grade GPU. For instance, they were able to perform fine tuning on a Vicuna-7B base model on an Nvidia A100 GPU in 5 hours with a fine tuning dataset consisting of 60k samples.
Medusa-2: Joint Training
The 2nd method for fine tuning is by jointly training the Medusa heads along with the base model. This fine tuning is done after the base model is pre-trained and requires some additional considerations.
To keep the base model’s next token prediction capability, its cross-entropy loss needs to be added to the loss of the medusa heads. So the overall loss function becomes:
Base model loss + λ0 * Medusa heads loss. Whereλ0is a weight parameter to balance the loss function.Although the Medusa heads are being trained from scratch, the base model is already pre-trained. Therefore, the paper suggests to use different learning rates for the base model and the prediction heads.
The paper also suggests warming up the Medusa heads by doing some pre-training while keeping the base model layers frozen, and then doing a joint training.
Speculative Decoding using the Medusa Architecture
Now, let’s talk about how speculative decoding works in the Medusa architecture.
As the Medusa architecture consists of k prediction heads, it predicts the next k tokens in a single inference pass. The current context vector is fed as input to the base LLM, and the embedding output from its last hidden layer goes as input to these prediction heads. Each head produces multiple candidate tokens for its corresponding position in the sequence, which results in the generation of a tree of possible continuations. The following illustration shows how this works for two prediction heads.

In order to avoid invalid continuations from being processed, such as [“jumps”, “eats”] the paper uses tree attention which masks out all such invalid constructions to cut down the amount of processing required to validate these continuations.
As we discussed when talking about the original speculative decoding scheme, it used rejection sampling for accepting the generated tokens. The reasoning behind doing that was to only accept tokens which are very close to what the base LLM would produce. However, the Medusa paper notes that in real-world the temperature parameter is used to generate more diverse output, and it should also allow a higher acceptance rate for the speculated tokens. Therefore, they came up with a different scheme for accepting tokens which takes this insight into account. Let’s see how this scheme works.
Acceptance of Generated Continuations in Medusa
The goal is to accept the most typical candidates, which means that even if they are not exactly what the base model would have produced, they are not exceedingly unlikely from the typical generations produced by the base model.
They achieve this using the prediction probability of the base model, combined with some thresholds. More specifically, if (x[1], x[2], x[3], …, x[n]) is the context vector and (x[n+1], x[n+2], …, x[n+k]) is a candidate continuation produced by the prediction heads, then they compute the acceptance of the x[n+k] token as follows:
This criteria is based on two motivations:
Tokens with high probability should be accepted
When the entropy is high, various possible continuations should be acceptable.
When verifying a continuation, each token is verified using the above criteria and the continuation with the longest accepted prefix is accepted.
To build intuition about this scheme, consider the following cases:
When the temperature is 0, any token with probability greater than the threshold ϵ will be accepted. This means only the tokens matching closely with the base LLM’s predictions will be accepted.
When the temperature value is increased, depending on the value of ϵ, and δ, more diverse tokens will be accepted, leading to an overall increased acceptance rate of the speculatively produced tokens.
The paper also notes that they always accept the first token greedily, i.e. they accept the most probable token for the first position, while they apply the above scheme on the rest of the tokens. This means that in the worst case they are at least producing one token.
Results of the Medusa Architecture
Let’s briefly look at the kind of speedups that the authors found with this architecture.
They used the Vicuna model of different sizes (7B, 13B, 33B) as the base model and they fine tuned the Medusa heads using the ShareGPT dataset for 2 epochs. In their experiments, they found a speed up of 2.18x on tokens processed per second for the Medusa-1 heads and 2.83x for the Medusa-2 heads, on the Vicuna-7B base model. The following graph shows the overall speedups.
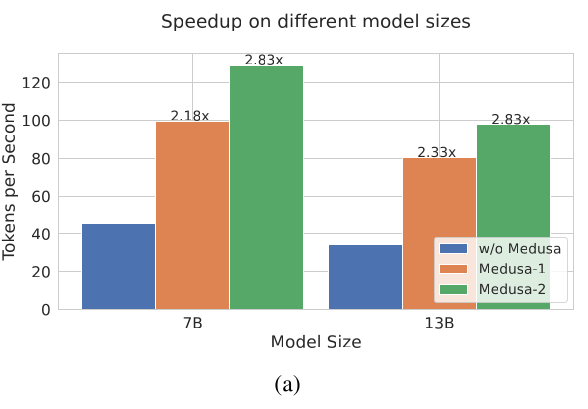
Modifications to the Medusa Architecture
Even though the speedups shown by the Medusa paper are impressive, it also has some limitations which were noted by the researchers at IBM in their experiments and they published it in the form of a report which also includes some interesting modifications.
Limitations of the Medusa Architecture
The Medusa model consists of multiple prediction heads which are used to predict the next k tokens. However, these heads receive the same input, which is the embedding vector as produced by the last hidden layer of the base model for predicting the current token. The further in the future a token is making a prediction, the further it moves away from the ground reality because it has no information about the previous token that was generated.
For instance, the kth head generating the kth next token doesn’t have any information about the token generated at the k-1 position. This means that these generations quickly deviate from the behavior of the base model and result in loss of accuracy, and reduced throughput.
The Proposed Modifications to Medusa
The authors propose a simple modification to the original Medusa architecture. They replace the multiple prediction heads with a multi-stage MLP. For instance, to predict the next k tokens, the speculator consists of a k stage MLP.
Each stage of the MLP takes as input the context vector and the output from the previous stage, which is passed through layer normalization or GeLU activation layer to form a state vector. Each stage produces the candidate tokens for the next position, leading to a tree of possible continuations as we saw in the Medusa architecture.

Verification of Candidate Continuations
Here, the authors deviate drastically from the verification technique used in the Medusa paper. As there are multiple candidate continuations, verifying them one by one is not optimal, so the authors switch to multi-candidate decoding technique for verifying the continuations in parallel. If there is enough compute resource available on the hardware, it can perform the verification faster and improve the overall token throughput.
The multi-candidate decoding technique is very similar to the technique we discussed for verifying a single token when discussing the original speculative decoding architecture from the ICML 2023 paper. However, in multi-candidate decoding multiple candidate continuations are batched together, and are verified in parallel by doing parallel inferences on the base LLM. I refer you to the paper by Chen et al. which explains this in detail.
Training of Multi-stage Medusa Heads
The authors also deviate from the Medusa paper in their training technique. Instead of training the speculator heads on the ground truth text, they froze the base LLM and used its output to train the speculator heads, with the goal of fully aligning the speculator with the base model to increase its accuracy.
They note that they were using the Llama model as the base LLM which is not highly parallelizable, therefore they broke the training of the speculator into two stages.
In the first stage, they used small batches of long contexts (4k tokens). For each batch, the base model would generate the embedding vector for each token in parallel which would then be fed into the speculator along with the ground truth tokens, to produce the subsequent tokens.
In the second stage, they used large batches of short contexts (256 tokens). They note that the reason for doing this was to continue the training efficiently while fine tuning the speculator to match the base model’s output explicitly.
They also mention that they roughly maintained a ratio of 5:2 for the number of steps for stage-1 versus stage-2 fine tuning. This resulted in half of the fine tuning time being spent in stage-1 and half in stage-2.
They report that after stage-2 fine tuning, a three-headed Llama-13B speculator went from 2.41 tokens per step (after stage-1) to 2.63 tokens per step.
Results of Multi-stage Medusa Architecture
The authors did not perform a direct comparison against the original Medusa architecture, or the original speculative decoding architecture, so it is not possible for me to put things in perspective. However, we can still discuss the results they obtained.
They measured the per token latency for different base models, for different batch sizes, context sizes, and different values of k (how many top-k predictions to select per head to generate the continuations).
For Llama-7B Chat
For three-headed Llama-7B Chat, they use the baseline as batch size = 1 and speculative decoding decoding, for this baseline the token latency was 10.54ms. Whereas they found almost 2x speed up in the latency for batch size 1 and k=4, at 5.50ms per token. Similarly, for prompt size 2048 tokens, they found the baseline to be at 12.87ms per token, and the latency after enabling speculative decoding at around 8.89ms per token for k=2.
These speedups appear to be less impressive than the numbers given in the Medusa paper, but the authors note that they were testing these in typical production settings, and these improvements largely depend on the available compute bandwidth of the GPU hardware. With increasing batch sizes, and context sizes, the prediction performance can even degrade when using speculative decoding.
For Llama-13B Chat
The authors also performed measurements on the Llama-13B chat model, and they observed a similar 2x drop in per token latency for batch size 1 and k=5. However, just like the 7B model, the efficiency gains disappear with larger batch sizes, which again hints towards the lack of compute bandwidth from the GPU hardware.
Codellama-13B-instruct
The authors also performed measurements on Codellama-13B-instruct. However, because tokens in this domain are more predictable, they increased the number of speculator heads from 3 to 7. They found a larger than 3x speedup in wall-clock time, and they were able to achieve a throughput of 181.5 tokens/s at fp16 precision.
Conclusion: Speculative Decoding and the Future of Efficient LLM Inference
Speculative decoding is a powerful technique to accelerate inference in autoregressive LLMs. It addresses the inherent bottleneck of sequential token generation. By employing a smaller, faster speculator model to propose candidate tokens, speculative decoding enables the main LLM to process multiple tokens in parallel, which significantly improves the token throughput and saves compute cost.
The original speculative decoding method relied on a separate draft model, introducing challenges in training, integration, and potential distribution mismatches. The Medusa architecture addressed these limitations by incorporating multiple prediction heads directly within the base LLM, eliminating the need for a separate speculator model. The Medusa paper showcases impressive speedups in terms of tokens processed per second, highlighting the effectiveness of this approach.
However, that is not the end of the story. Even though Medusa improves upon the original speculative decoding design, it also has some limitations which were outlined in the IBM report. They suggest some interesting modifications, such as using a multi-stage MLP and employing multi-candidate decoding for faster verification of candidate tokens. This shows that there is still a lot of scope of improvement in this area.
With the wide adoption of LLMs across organizations, the demand for faster and cost-effective inference is growing. Techniques like speculative decoding, model compression, and quantization are already widely deployed. Inference optimization is a hot area which is worth keeping an eye on for more such developments which will drive the cost of inference further down.
Support Confessions of a Code Addict
If you find my work interesting and valuable, you can support me by opting for a paid subscription (it’s $6 monthly/$60 annual). As a bonus you get access to monthly live sessions, and all the past recordings.
Many people report failed payments, or don’t want a recurring subscription. For that I also have a buymeacoffee page. Where you can buy me coffees or become a member. I will upgrade you to a paid subscription for the equivalent duration here.
I also have a GitHub Sponsor page. You will get a sponsorship badge, and also a complementary paid subscription here.